

Apache Kafka: tutorial para los primeros pasos

El software de código abierto Apache Kafka es una de las mejores soluciones para almacenar y procesar flujos de datos. Esta plataforma de mensajería y transmisión, publicada bajo la licencia de Apache 2.0, destaca por su tolerancia a los errores, su excelente escalabilidad y su gran velocidad de lectura y escritura. Estas características, que resultan sumamente interesantes para las aplicaciones de big data, se basan en una red de ordenadores (denominada clúster) que hace posible almacenar y replicar datos de manera distribuida. La comunicación con el clúster se establece a través de cuatro interfaces distintas, siendo suficiente un simple protocolo TCP.
Con este tutorial de Kafka, aprenderás las funciones más básicas de esta aplicación escrita en Scala, empezando por la instalación de Kafka y de otro software necesario para utilizarla: Apache ZooKeeper.
Requisitos para utilizar Apache Kafka
Para poder ejecutar el potente clúster de Kafka, se necesita un hardware adecuado. El equipo de desarrolladores del programa recomienda utilizar procesadores Intel Xeon de cuatro núcleos con memoria de 24 gigabytes. En principio, necesitarás suficiente memoria para poder almacenar en todo momento en caché los accesos de lectura y escritura de todas las aplicaciones que accedan activamente al clúster. Dado que el alto rendimiento de los datos es una de las ventajas particulares de Apache Kafka, es de vital importancia elegir unas unidades de disco duro apropiadas. Apache Software Foundation recomienda las unidades de disco duro SATA (8 x 7200 RPM). Para evitar cuellos de botella en el rendimiento, el principio general es que cuantas más unidades haya, mejor.
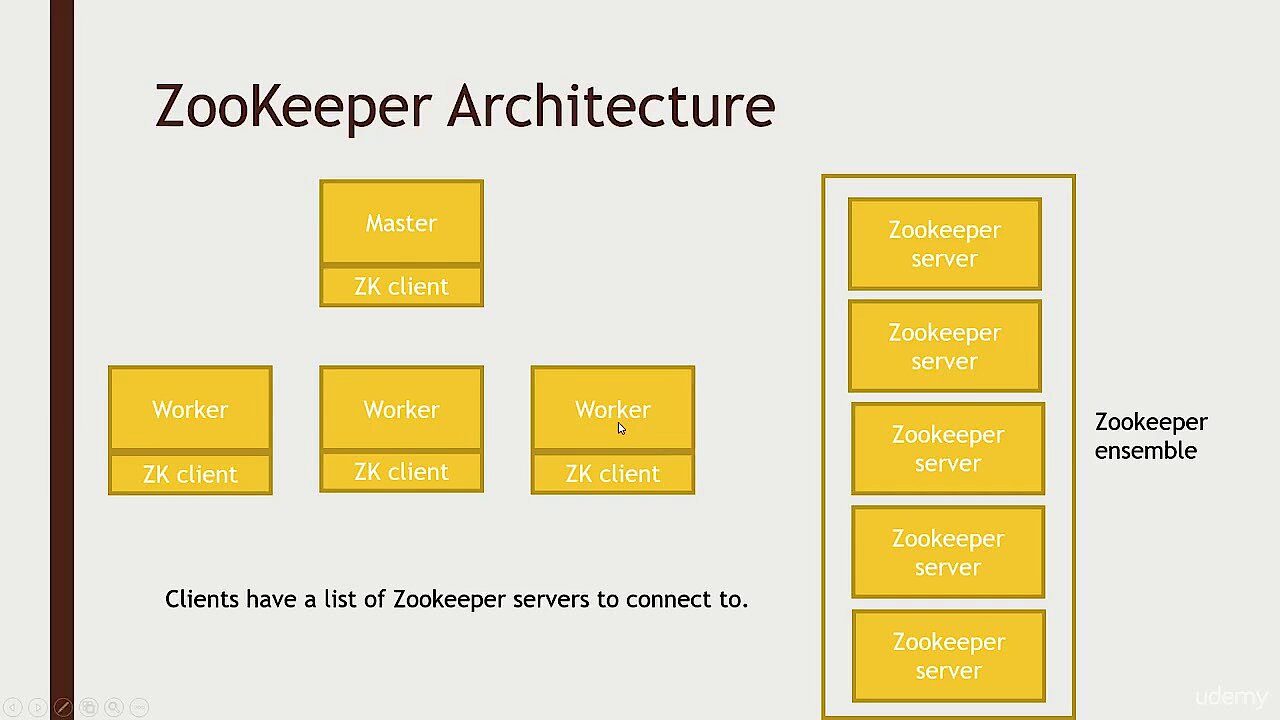
También en términos de software, se deben cumplir algunos requisitos para poder utilizar Apache Kafka para gestionar flujos de datos entrantes y salientes. Por ejemplo, cuando elijas el sistema operativo, deberías decantarte por un sistema UNIX como Solaris o una distribución de Linux, ya que la compatibilidad con las plataformas de Windows es limitada. Dado que Apache Kafka está escrito en lenguaje Scala, compilado en Java, conviene que tengas instalada una versión actualizada del Java Development Kit (JDK) en tu sistema. Lo mismo se aplica, entre otros, al Java Runtime Environment, necesario para ejecutar aplicaciones Java. Otro componente obligatorio es el servicio Apache ZooKeeper, que permite la sincronización de procesos en sistemas distribuidos.
 Para mostrar este video, se requieren cookies de terceros. Puede acceder y cambiar sus ajustes de cookies aquí.
Para mostrar este video, se requieren cookies de terceros. Puede acceder y cambiar sus ajustes de cookies aquí. Apache Kafka: tutorial para instalar Kafka, ZooKeeper y Java
En el anterior apartado de este tutorial de Kafka, explicamos los componentes de software necesarios para utilizarlo. A menos que ya lo tengas configurado en tu sistema, lo mejor es comenzar instalando Java Runtime Environment. Muchas versiones recientes de las distribuciones de Linux, como Ubuntu, el sistema operativo que nos sirve de ejemplo en este tutorial de Apache Kafka (versión 17.10), ya incluyen una implementación gratuita del JDK (Java Develompent Kit) en su repositorio de paquetes oficial, llamada OpenJDK. Para instalar fácilmente el kit de Java a través de esta implementación, introduce el siguiente comando en el terminal:
sudo apt-get install openjdk-8-jdkUna vez hayas instalado Java, haz lo mismo con el servicio de sincronización de procesos Apache ZooKeeper. El directorio de paquetes de Ubuntu también contiene un paquete listo para utilizar en este caso, que se ejecuta con el siguiente comando:
sudo apt-get install zookeeperdCon este otro comando, puedes verificar si el servicio de ZooKeeper está activo:
sudo systemctl status zookeeperSi Apache ZooKeeper se está ejecutando, tendrías que ver algo así:


Si el servicio de sincronización no se está ejecutando, puedes iniciarlo en cualquier momento con este comando:
sudo systemctl start zookeeperA continuación, para asegurarte de que ZooKeeper se ejecute automáticamente cada vez que inicies el sistema, introduce un comando de inicio automático:
sudo systemctl enable zookeeperFinalmente, tendrás que crear un perfil de usuario de Kafka para volver a utilizar el servidor más adelante. Para ello, vuelve a abrir el terminal y escribe el siguiente comando:
sudo useradd kafka -mMediante el administrador de contraseñas passwd, puedes asignar al usuario la contraseña que desees, escribiendo primero el comando y luego la contraseña:
sudo passwd kafkaEn el siguiente paso, le concederás derechos sudo al usuario «kafka»:
sudo adduser kafka sudoCon el perfil de usuario que acabas de crear, puedes iniciar sesión en cualquier momento:
su – kafkaLlegados a este punto del tutorial, ya podemos descargar e instalar Kafka. Existen muchas fuentes de descarga fiables que ofrecen versiones actuales y anteriores de este software de procesamiento de flujos. Por ejemplo, puedes obtener los archivos de instalación de primera mano en el directorio de descargas de Apache Software Foundation. Te recomendamos disponer de una versión actualizada de Kafka, por lo que, al escribir el siguiente comando en el terminal, quizás tengas que adaptarlo a la nueva versión:
wget http://www.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgzEl siguiente paso es descomprimir el archivo comprimido que te has descargado:
sudo tar xvzf kafka_2.12-2.1.0.tgz --strip 1Utiliza el parámetro «--strip 1» para asegurarte de que los archivos extraídos se almacenan directamente en el directorio «~/Kafka». De lo contrario, Ubuntu pondría todos los archivos en el directorio «~/kafka/kafka_2.12-2.1.0», según la versión utilizada en este tutorial de Kafka. El requisito es que hayas creado previamente un directorio llamado «Kafka» mediante mkdir y lo hayas cambiado con «cd Kafka».
Kafka: tutorial para configurar el sistema de transmisión y mensajería
Ahora que has instalado Apache Kafka, Java Runtime Environment y ZooKeeper, en principio podrás ejecutar el servicio de Kafka en cualquier momento. Sin embargo, antes de hacerlo, debes llevar a cabo unas pequeñas configuraciones para que el software ejecute todas las tareas de manera óptima en el futuro.
Desbloquear la eliminación de topics
En su configuración predeterminada, Kafka no permite eliminar topics, es decir, las unidades de almacenamiento y categorización de un clúster de Kafka, aunque esto puede modificarse fácilmente mediante el archivo de configuración server.properties. Para abrir este archivo, que se encuentra en la carpeta «config», introduce el siguiente comando en el editor de texto nano estándar:
sudo nano ~/kafka/config/server.propertiesDespués de este archivo de configuración, introduce una nueva entrada que permita eliminar los topics de Kafka:
delete.topic.enable=true

No te olvides de guardar la nueva entrada en el archivo de configuración de Kafka antes de cerrar el editor nano.
Crear archivos .service para ZooKeeper y Kafka
El siguiente paso de este tutorial de Kafka es crear archivos Unit para ZooKeeper y Kafka que permitan realizar acciones habituales como iniciar, detener o reiniciar ambos servicios en consonancia con otros servicios de Linux. Para ello, es necesario crear y configurar los archivos .service para el administrador de sesiones systemd para ambas aplicaciones.
Cómo crear un archivo de ZooKeeper para el administrador de sesiones systemd de Ubuntu
Primero, crea el archivo para el servicio de sincronización de ZooKeeper introduciendo el siguiente comando en el terminal:
sudo nano /etc/systemd/system/zookeeper.serviceCon esto no solo crearás el archivo, sino que también lo abrirás en el editor nano. Introduce las siguientes líneas y, luego, guarda el archivo:
[Unit]
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
ExecStart=/home/kafka/kafka/bin/zookeeper-server-start.sh /home/kafka/kafka/config/zookeeper.properties
ExecStop=/home/kafka/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetComo resultado, systemd entenderá que ZooKeeper no puede iniciarse hasta que la red y el sistema de archivos estén listos, como se define en la sección [Unit]. En [Service] se especifica que el administrador de sesión debe utilizar los archivos zookeeper-server-start.sh y zookeeper-server-stop.sh para iniciar y detener ZooKeeper. Además, se define un reinicio automático para los casos en los que el servicio se detenga de improviso. La entrada [Install] regula cuándo se inicia el archivo, estableciendo «multi-user.target» como valor predeterminado para un sistema multiusuario (por ejemplo, un servidor).
Cómo crear un archivo de Kafka para el administrador de sesiones systemd de Ubuntu
El archivo .service de Apache Kafka se puede crear escribiendo el siguiente comando en el terminal:
sudo nano /etc/systemd/system/kafka.serviceEn el nuevo archivo que se abrirá en el editor nano, copia el siguiente contenido:
[Unit]
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User=kafka
ExecStart=/bin/sh -c '/home/kafka/kafka/bin/kafka-server-start.sh /home/kafka/kafka/config/server.properties > /home/kafka/kafka/kafka.log 2>&1'
ExecStop=/home/kafka/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetEn la sección [Unit] de este archivo, se especifica que el servicio de Kafka depende de ZooKeeper, lo que asegura que el servicio de sincronización también se inicie cuando se ejecute el archivo kafka.service. Bajo [Service], se introducen los archivos del shell kafka-server-start.sh y kafka-server-stop.sh para iniciar o detener el servidor de Kafka. En este archivo también se especifica el reinicio automático en caso de caída de la conexión, así como la entrada referente al sistema multiusuario.


Kafka: primer arranque y creación de una entrada de inicio automático
Una vez hayas creado con éxito las entradas del administrador de sesiones para Kafka y ZooKeeper, puedes iniciar Kafka de la siguiente manera:
sudo systemctl start kafkaDe forma predeterminada, el programa systemd utiliza un protocolo central o journal en el que todos los mensajes de registro se escriben automáticamente. Gracias a esta característica, te será fácil comprobar si el servidor Kafka se ha iniciado como deseas:
sudo journalctl -u kafkaEl output debería tener este aspecto:


Si el inicio manual de Apache Kafka funciona, puedes activar finalmente el inicio automático como parte del inicio del sistema:
sudo systemctl enable kafkaApache Kafka: tutorial para dar los primeros pasos
Ha llegado el momento de probar Apache Kafka. Antes que nada, deberás procesar un primer mensaje utilizando la plataforma de mensajería. Para ello, necesitarás un productor y un consumidor, es decir, una instancia que permita escribir y publicar datos en topics, así como una instancia que pueda leer los datos de los topics. En primer lugar, crearás un topic, que se llamará TutorialTopic en este caso. Como se trata de un topic sencillo a modo de prueba, tan solo incluirá una partición y una réplica:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic TutorialTopicA continuación, crea un productor que inserte un primer mensaje de muestra (como «¡Hola, mundo!») en el topic que acabas de establecer. Para ello, utiliza el script de shell kafka-console-producer.sh, que recibirá el nombre del host, el puerto del servidor (en el ejemplo: ruta predeterminada de Kafka) y el nombre del topic como argumentos:
echo "¡Hola, mundo!" | ~/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic TutorialTopic > /dev/nullUtilizando el script kafka-console-consumer.sh, crearás un consumidor de Kafka que procesará y renderizará mensajes de TutorialTopic. De nuevo, el nombre del host y el puerto del servidor de Kafka y el nombre del topic son necesarios como argumentos. Además, se añadirá el argumento «--from-beginning» para que el mensaje «¡Hola, mundo!», que en este caso se publicó antes de que el consumidor se iniciara, pueda ser procesado por este:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic TutorialTopic --from-beginningComo resultado, el mensaje «¡Hola, mundo!» aparece en el terminal, con el script ejecutándose y esperando a que se publiquen más mensajes en el topic de prueba. Por lo tanto, si introduces más datos en otra ventana del terminal mediante el productor, también deberías verlos en la ventana donde se ejecuta el script del consumidor.

